如果想要尝试被动扩缩容,用户可以增加 scheduler-mode: reactive 这一配置项,然后启动一个应用集群(Standalone 或者 K8s)。更多细节见被动扩缩容的文档。
分析应用的性能
对所有应用程序来说,能够简单的分析和理解应用的性能是非常关键的功能。这一功能对 Flink 更加重要,因为 Flink 应用一般是数据密集的(即需要处理大量的数据)并且需要在(近)实时的延迟内给出结果。
当 Flink 应用处理的速度跟不上数据输入的速度时,或者当一个应用占用的资源超过预期,下文介绍的这些工具可以帮你分析原因。
瓶颈检测与反压监控
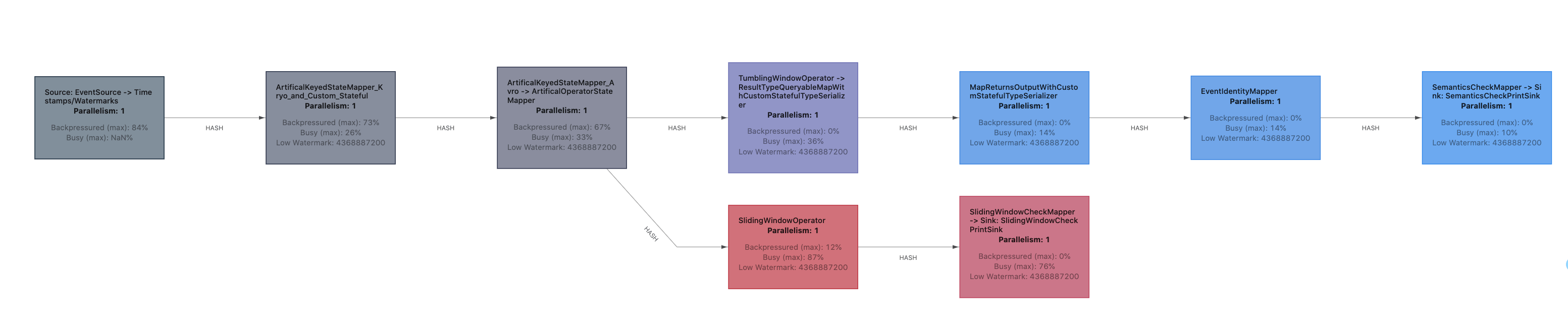
Flink 性能分析首先要解决的问题经常是:哪个算子是瓶颈?
为了回答这一问题,Flink 引入了描述作业繁忙(即在处理数据)与反压(由于下游算子不能及时处理结果而无法继续输出)程度的指标。应用中可能的瓶颈是那些繁忙并且上游被反压的算子。
Flink 1.13 优化了反压检测的逻辑(使用基于任务 Mailbox 计时,而不在再于堆栈采样),并且重新实现了作业图的 UI 展示:Flink 现在在 UI 上通过颜色和数值来展示繁忙和反压的程度。
Web UI 中的 CPU 火焰图
Flink 关于性能另一个经常需要回答的问题:瓶颈算子中的哪部分计算逻辑消耗巨大?
针对这一问题,一个有效的可视化工具是火焰图。它可以帮助回答以下问题:
- 哪个方法调现在在占用 CPU?
- 不同方法占用 CPU 的比例如何?
- 一个方法被调用的栈是什么样子的?
火焰图是通过重复采样线程的堆栈来构建的。在火焰图中,每个方法调用被表示为一个矩形,矩形的长度与这个方法出现在采样中的次数成正比。火焰图在 UI 上的一个例子如下图所示。
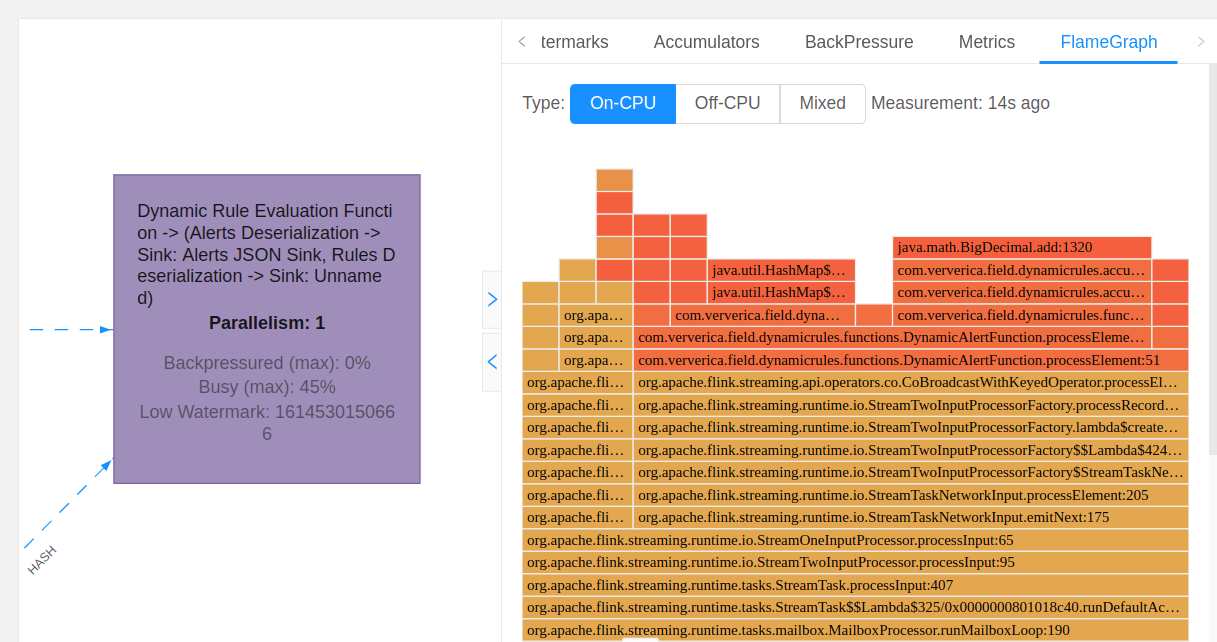
火焰图的文档包括启用这一功能的更多细节和指令。
State 访问延迟指标
另一个可能的性能瓶颈是 state backend,尤其是当作业的 state 超过内存容量而必须使用 RocksDB state backend 时。
这里并不是想说 RocksDB 性能不够好(我们非常喜欢 RocksDB!),但是它需要满足一些条件才能达到最好的性能。例如,用户可能很容易遇到非故意的在云上由于使用了错误的磁盘资源类型而不能满足 RockDB 的 IO 性能需求的问题。
基于 CPU 火焰图,新的 State Backend 的延迟指标可以帮助用户更好的判断性能不符合预期是否是由 State Backend 导致的。例如,如果用户发现 RocksDB 的单次访问需要几毫秒的时间,那么就需要查看内存和 I/O 的配置。这些指标可以通过设置 state.backend.rocksdb.latency-track-enabled 这一选项来启用。这些指标是通过采样的方式来监控性能的,所以它们对 RocksDB State Backend 的性能影响是微不足道的。