不是所有图像都值16x16个词,清华与华为提出动态(2)
2021-06-05 13:01 量子位
研究团队在此基础上,还进一步提出了 特征重用机制和 关系重用机制,它们都能够通过最小化计算成本来显著提高测试精度,以减少冗余计算。
前者允许在先前提取的深度特征的基础上训练下游数据,而后者可以利用现有的上游的自注意力模型来学习更准确的注意力。
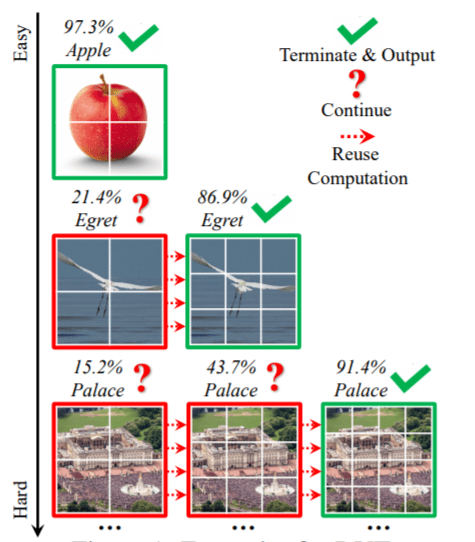
这种对“简单”“困难”动态分配的方法,其现实效果可以由下图的实例给出说明。
那么,接下来让我们来看看这两种机制具体是怎么做的?
特征重用机制
因此,下游模型应该在之前获得的深度特征的基础上进行学习,而不是从零开始提取特征。
在上游模型中执行的计算对其自身和后续模型都有贡献,这样会使模型效率更高。
为了实现这个想法,研究团队提出了一个特征重用机制。
简单来说,就是利用上游Transformer最后一层输出的图像tokens,来学习逐层的上下文嵌入,并将其集成到每个下游Transformer的MLP块中。
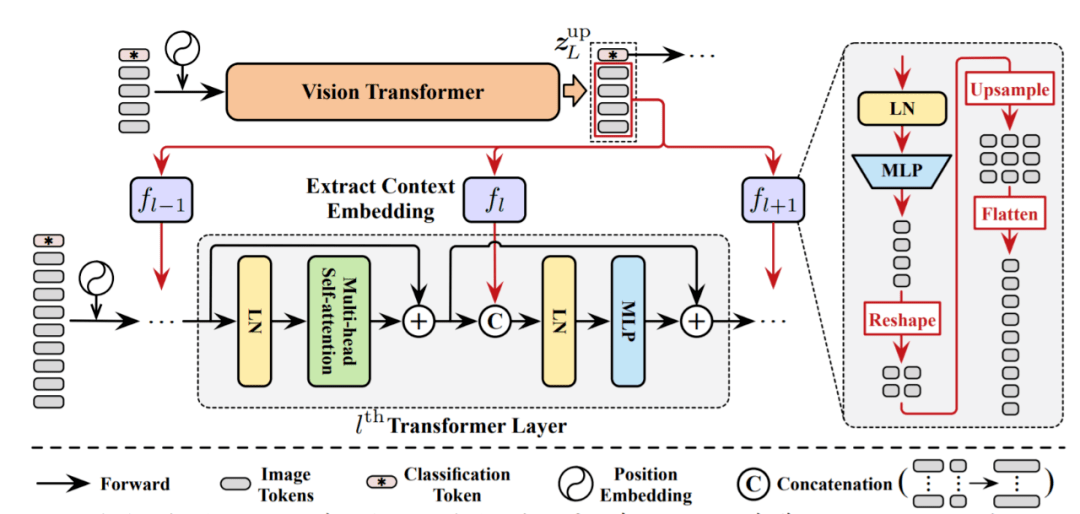
关系重用机制
Transformer的一个突出优点是:
自注意力块能够整合整个图像中的信息,从而有效地模型化了数据中的长期依赖关系。
通常,模型需要在每一层学习一组注意力图来描述标记之间的关系。
除了上面提到的深层特征外,下游模型还可以获得之前模型中产生的自注意力图。
研究团队认为,这些学习到的关系也能够被重用,以促进下游Transformer学习,具体采用的是对数的加法运算。

效果如何?
多说无益,让我们看看实际效果如何?
在ImageNet上的 Top-1准确率v.s.吞吐量如下图。
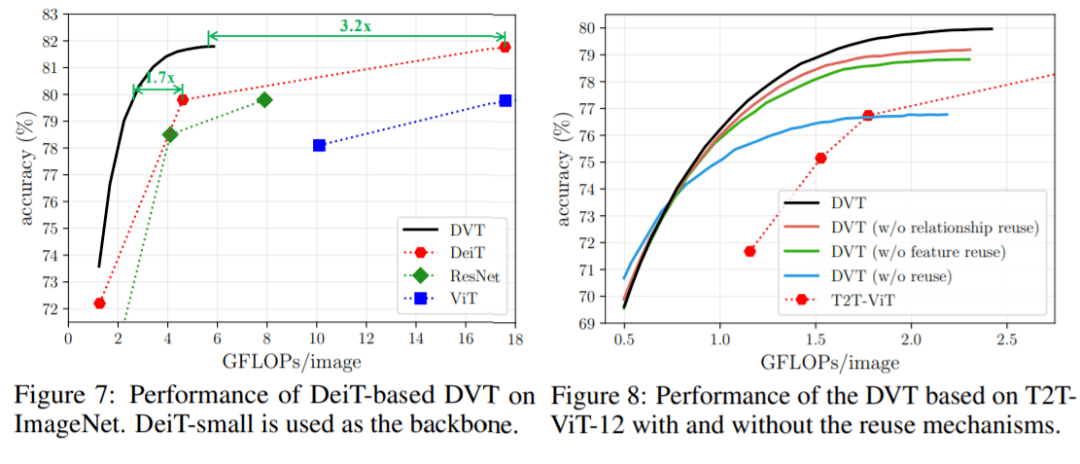
可以看出,DVT比T2T-VIT计算效果要更好:
当预算范围在0.5-2 GFLOPs内时,DVT的计算量比相同性能的T2T-ViT少了1.7-1.9倍。
此外,这种方法可以灵活地达到每条曲线上的所有点,只需调整一次DVT的置信阈值即可。
官方微信公众号:掌酷门户(wapzknet)
相关资讯
新闻热点
精选美图