不是所有图像都值16x16个词,清华与华为提出动态(3)
2021-06-05 13:01 量子位
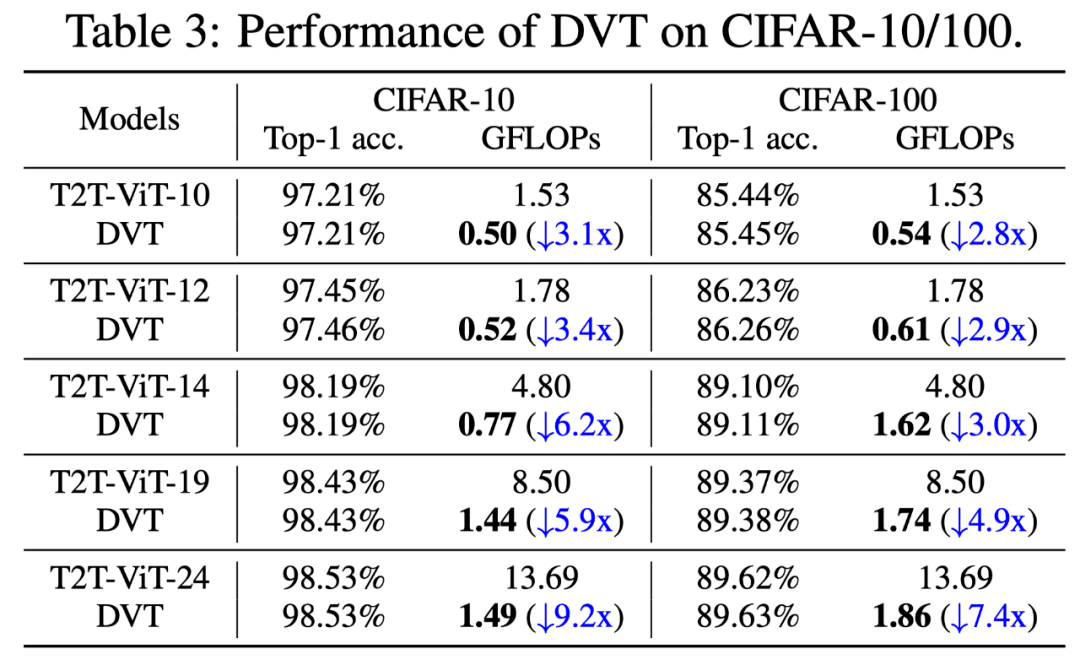
CIFAR的 Top-1 准确率 v.s. GFLOP 如下图。
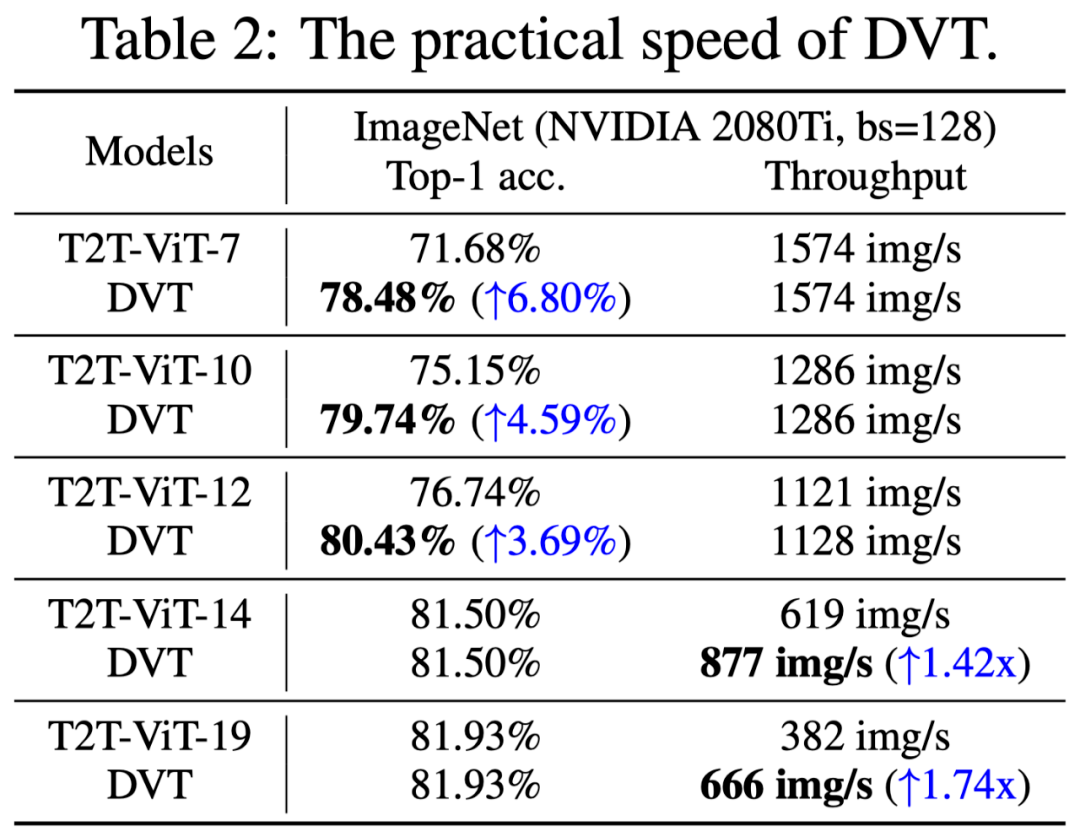
在ImageNet上的 Top-1准确率v.s.吞吐量如下表。
在DVT中,“简单”和 “困难”的可视化样本如下图。

从上面ImageNet、CIFAR-10 和 CIFAR-100 上的大量实证结果表明:
DVT方法在理论计算效率和实际推理速度方面,都明显优于其他方法。
看到这样漂亮的结果,难道你还不心动吗?
有兴趣的小伙伴欢迎去看原文哦~
传送门
论文地址:
https://arxiv.org/abs/2105.15075
研究团队

黄高
目前年仅33岁,已是清华大学自动化系助理教授,博士生导师。
获得过2020年阿里巴巴达摩院青橙奖,研究领域包括机器学习、深度学习、计算机视觉、强化学习等。
— 完—
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
致敬科技工作者,计算资源免费送!
为致敬5.30“全国科技工作者日”、助力科研升级转型,并行科技联合量子位推出算力资源赠送及促销活动。
6月9日前,扫码可 免费领取5000核时CPU计算资源、或500元卡时GPU计算资源,更有多重算力促销优惠活动,快来参与吧~
点这里
官方微信公众号:掌酷门户(wapzknet)
相关资讯
新闻热点
精选美图