水木番 发自 凹非寺
量子位 报道 | 公众号 QbitAI
尤其是,ViT在大规模图像网络上性能特别高,因此应用特别广。
但随着数据集规模的增长, 会导致计算成本急剧增加,以及自注意力中的tokens数量逐渐增长!
最近,清华自动化系的助理教授 黄高的研究团队和华为的研究人员 另辟蹊径,提出了一种Dynamic Vision Transformer (DVT),可以自动为每个输入图像配置适当数量的tokens,从而减少冗余计算,显著通过效率。
该文以 《Not All Images are Worth 16x16 Words: Dynamic Vision Transformers with Adaptive Sequence Length》为标题,已发表在arXiv上。
提出动态ViT
很明显,当前的ViT面临计算成本和tokens数量的难题。
为了在准确性和速度之间实现最佳平衡,tokens的数量一般是 14x14/16x16的。
研究团队观察到:
一般样本中会有很多的“简单”图像,它们用数量为 4x4 标记就可以准确预测,现在的计算成本( 14x14)相当于增加了8.5倍,而其实只有一小部分“困难”的图像需要更精细的表征。
通过动态调整tokens数量,计算效率在“简单”和 “困难”样本中的分配并不均匀,这里有很大的空间可以提高效率。
基于此,研究团队提出了一种新型的 动态ViT(DVT )框架,目标是 自动配置在每个图像上调节的tokens数量 ,从而实现高计算效率。
这种DVT被设计成一个通用框架。
在测试时间时,这些模型以较少的tokens 开始依次被激活。
一旦产生了充分置信度的预测,推理过程就会立即终止。
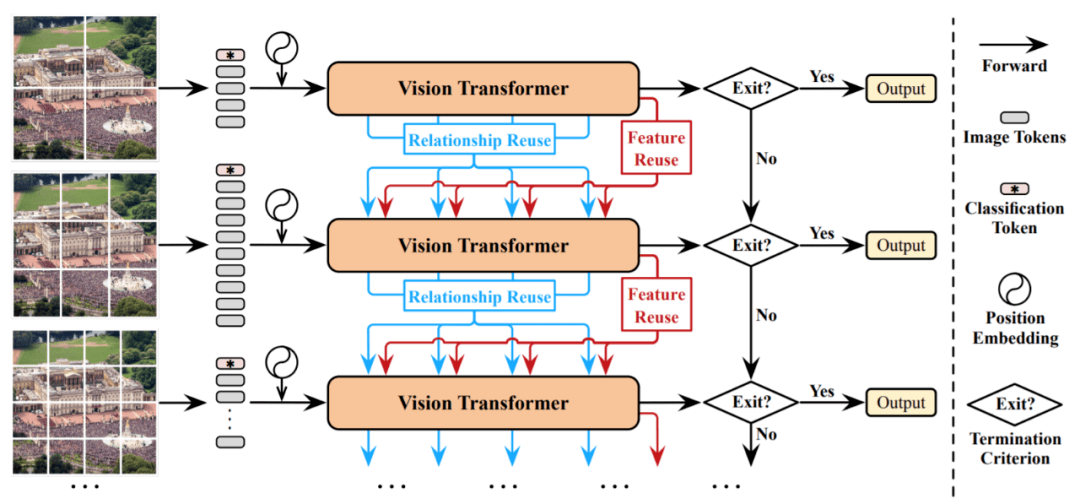
这种方法同时也具有很强的 灵活性。
因为DVT的计算量可以通过简单的 提前终止准则进行调整。
这一特性使得DVT适合可用计算资源动态变化,或通过最小功耗来实现给定性能的情况。
这两种情况在现实世界的应用程序中都是普遍存在的,像搜索引擎和移动应用程序中都经常能够看到。
根据上面的流程图,仔细的读者还会发现:
一旦从上游往下游计算无法成功的时候,就会采取向先前信息或者上游信息进行重用的方法实现进一步数据训练。