像聚类算法一样,降低维度算法试图分析数据的内在结构,不过降低维度算法是以非监督学习的方式试图利用较少的信息来归纳或者解释数据。这类算法可以用于高维数据的可视化或者用来简化数据以便监督式学习使用。
常见的算法包括:主成份分析(Principle Component Analysis, PCA),偏最小二乘回归(Partial Least Square Regression,PLS), Sammon映射,多维尺度(Multi-Dimensional Scaling, MDS), 投影追踪(Projection Pursuit)等。
17. 集成算法:
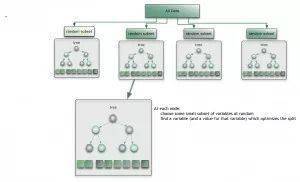
集成算法用一些相对较弱的学习模型独立地就同样的样本进行训练,然后把结果整合起来进行整体预测。集成算法的主要难点在于究竟集成哪些独立的较弱的学习模型以及如何把学习结果整合起来。
这是一类非常强大的算法,同时也非常流行。常见的算法包括:Boosting, Bootstrapped Aggregation(Bagging), AdaBoost,堆叠泛化(Stacked Generalization, Blending),梯度推进机(Gradient Boosting Machine, GBM),随机森林(Random Forest)。
常见机器学习算法优缺点:
朴素贝叶斯:
1. 如果给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分类为例),比如说是句子单词的话,则长度为整个词汇量的长度,对应位置是该单词出现的次数。
2. 计算公式如下:
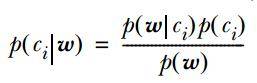
其中一项条件概率可以通过朴素贝叶斯条件独立展开。要注意一点就是 的计算方法,而由朴素贝叶斯的前提假设可知,=,因此一般有两种,一种是在类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本的总和;第二种方法是类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本中所有特征出现次数的总和。
3. 如果 中的某一项为0,则其联合概率的乘积也可能为0,即2中公式的分子为0,为了避免这种现象出现,一般情况下会将这一项初始化为1,当然为了保证概率相等,分母应对应初始化为2(这里因为是2类,所以加2,如果是k类就需要加k,术语上叫做laplace光滑, 分母加k的原因是使之满足全概率公式)。
朴素贝叶斯的优点:对小规模的数据表现很好,适合多分类任务,适合增量式训练。
缺点:对输入数据的表达形式很敏感。
决策树:决策树中很重要的一点就是选择一个属性进行分枝,因此要注意一下信息增益的计算公式,并深入理解它。