信息熵的计算公式如下:

其中的n代表有n个分类类别(比如假设是2类问题,那么n=2)。分别计算这2类样本在总样本中出现的概率p1和p2,这样就可以计算出未选中属性分枝前的信息熵。
现在选中一个属性xi用来进行分枝,此时分枝规则是:如果xi=vx的话,将样本分到树的一个分支;如果不相等则进入另一个分支。很显然,分支中的样本很有可能包括2个类别,分别计算这2个分支的熵H1和H2,计算出分枝后的总信息熵H’=p1*H1+p2*H2.,则此时的信息增益ΔH=H-H’。以信息增益为原则,把所有的属性都测试一边,选择一个使增益最大的属性作为本次分枝属性。
决策树的优点:计算量简单,可解释性强,比较适合处理有缺失属性值的样本,能够处理不相关的特征;
缺点:容易过拟合(后续出现了随机森林,减小了过拟合现象)。
Logistic回归:Logistic是用来分类的,是一种线性分类器,需要注意的地方有:
1. logistic函数表达式为:

其导数形式为:

2. logsitc回归方法主要是用最大似然估计来学习的,所以单个样本的后验概率为:
![]()
到整个样本的后验概率:
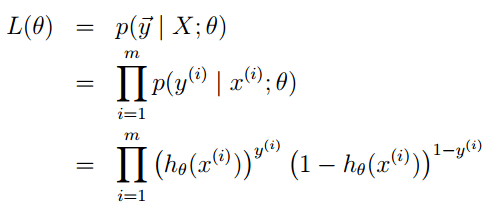
其中:
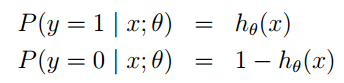
通过对数进一步化简为:
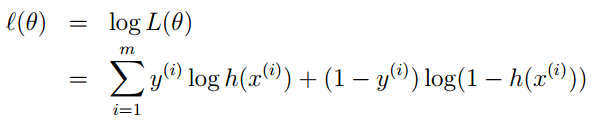
3. 其实它的loss function为-l(θ),因此我们需使loss function最小,可采用梯度下降法得到。梯度下降法公式为:
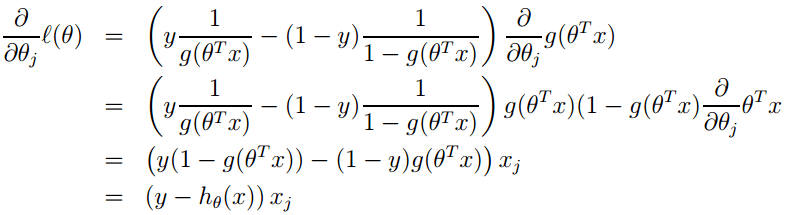
![]()
Logistic回归优点:
1. 实现简单
2. 分类时计算量非常小,速度很快,存储资源低;
缺点:
1. 容易欠拟合,一般准确度不太高
2. 只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
线性回归:
线性回归才是真正用于回归的,而不像logistic回归是用于分类,其基本思想是用梯度下降法对最小二乘法形式的误差函数进行优化,当然也可以用normal equation直接求得参数的解,结果为: