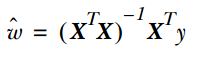
而在LWLR(局部加权线性回归)中,参数的计算表达式为:

因为此时优化的是:
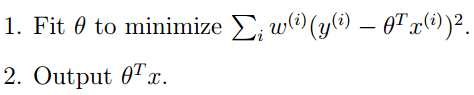
由此可见LWLR与LR不同,LWLR是一个非参数模型,因为每次进行回归计算都要遍历训练样本至少一次。
线性回归优点:实现简单,计算简单;
缺点:不能拟合非线性数据;
KNN算法:KNN即最近邻算法,其主要过程为:
1. 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等);
2. 对上面所有的距离值进行排序;
3. 选前k个最小距离的样本;
4. 根据这k个样本的标签进行投票,得到最后的分类类别;
如何选择一个最佳的K值,这取决于数据。一般情况下,在分类时较大的K值能够减小噪声的影响。但会使类别之间的界限变得模糊。一个较好的K值可通过各种启发式技术来获取,比如,交叉验证。另外噪声和非相关性特征向量的存在会使K近邻算法的准确性减小。
近邻算法具有较强的一致性结果。随着数据趋于无限,算法保证错误率不会超过贝叶斯算法错误率的两倍。对于一些好的K值,K近邻保证错误率不会超过贝叶斯理论误差率。
注:马氏距离一定要先给出样本集的统计性质,比如均值向量,协方差矩阵等。关于马氏距离的介绍如下:

KNN算法的优点:
1. 思想简单,理论成熟,既可以用来做分类也可以用来做回归;
2. 可用于非线性分类;
3. 训练时间复杂度为O(n);
4. 准确度高,对数据没有假设,对outlier不敏感;
缺点:
1. 计算量大;
2. 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);
3. 需要大量的内存;
SVM:
要学会如何使用libsvm以及一些参数的调节经验,另外需要理清楚svm算法的一些思路:
1. svm中的最优分类面是对所有样本的几何裕量最大(为什么要选择最大间隔分类器,请从数学角度上说明?网易深度学习岗位面试过程中有被问到。答案就是几何间隔与样本的误分次数间存在关系:
![]()
,其中的分母就是样本到分类间隔距离,分子中的R是所有样本中的最长向量值),即: