缺点:
(1)k-平均方法只有在簇的平均值被定义的情况下才能使用,且对有些分类属性的数据不适合。
(2)要求用户必须事先给出要生成的簇的数目k。
(3)对初值敏感,对于不同的初始值,可能会导致不同的聚类结果。
(4)不适合于发现非凸面形状的簇,或者大小差别很大的簇。
(5)对于"噪声"和孤立点数据敏感,少量的该类数据能够对平均值产生极大影响。
2. 基于层次的聚类:
自底向上的凝聚方法,比如AGNES。
自上向下的分裂方法,比如DIANA。
3. 基于密度的聚类:DBSACN,OPTICS,BIRCH(CF-Tree),CURE.
4. 基于网格的方法:STING, WaveCluster.
5. 基于模型的聚类:EM,SOM,COBWEB.
推荐系统:推荐系统的实现主要分为两个方面:基于内容的实现和协同滤波的实现。
基于内容的实现:不同人对不同电影的评分这个例子,可以看做是一个普通的回归问题,因此每部电影都需要提前提取出一个特征向量(即x值),然后针对每个用户建模,即每个用户打的分值作为y值,利用这些已有的分值y和电影特征值x就可以训练回归模型了(最常见的就是线性回归)。
这样就可以预测那些用户没有评分的电影的分数。(值得注意的是需对每个用户都建立他自己的回归模型)
从另一个角度来看,也可以是先给定每个用户对某种电影的喜好程度(即权值),然后学出每部电影的特征,最后采用回归来预测那些没有被评分的电影。
当然还可以是同时优化得到每个用户对不同类型电影的热爱程度以及每部电影的特征。
基于协同滤波的实现:协同滤波(CF)可以看做是一个分类问题,也可以看做是矩阵分解问题。协同滤波主要是基于每个人自己的喜好都类似这一特征,它不依赖于个人的基本信息。
比如刚刚那个电影评分的例子中,预测那些没有被评分的电影的分数只依赖于已经打分的那些分数,并不需要去学习那些电影的特征。
SVD将矩阵分解为三个矩阵的乘积,公式如下所示:
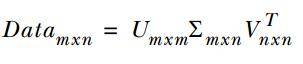
中间的矩阵sigma为对角矩阵,对角元素的值为Data矩阵的奇异值(注意奇异值和特征值是不同的),且已经从大到小排列好了。即使去掉特征值小的那些特征,依然可以很好的重构出原始矩阵。如下图所示:
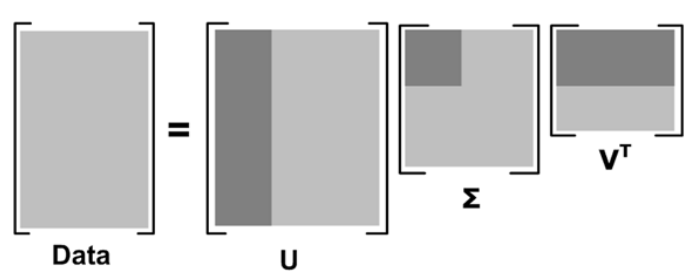
其中更深的颜色代表去掉小特征值重构时的三个矩阵。
果m代表商品的个数,n代表用户的个数,则U矩阵的每一行代表商品的属性,现在通过降维U矩阵(取深色部分)后,每一个商品的属性可以用更低的维度表示(假设为k维)。这样当新来一个用户的商品推荐向量X,则可以根据公式X'*U1*inv(S1)得到一个k维的向量,然后在V’中寻找最相似的那一个用户(相似度测量可用余弦公式等),根据这个用户的评分来推荐(主要是推荐新用户未打分的那些商品)。