SQL任务运行时间省40%,后悔没早从Hive迁到Spark…(2)
2021-06-02 09:45 dbaplus社群
开发一个SQL双跑工具,可以支持使用两个引擎执行同一个SQL任务;
下面详细介绍这两个方案:
1. 方案一:复用现有的SQL任务调度系统
再部署一套SQL任务执行系统用来使用Spark执行所有的SQL,包括HDFS,HiveServer2&MetaStore和Spark,DataStudio。新部署的系统需要周期性从生产环境同步任务信息,元数据信息和HDFS数据,在这个新部署的系统中把Hive SQL任务改成Spark SQL类型任务,这样一个用户的SQL在原有系统中使用Hive SQL执行,在新部署的系统中使用Spark执行。如下图所示,蓝色的表示需要新部署的子系统。
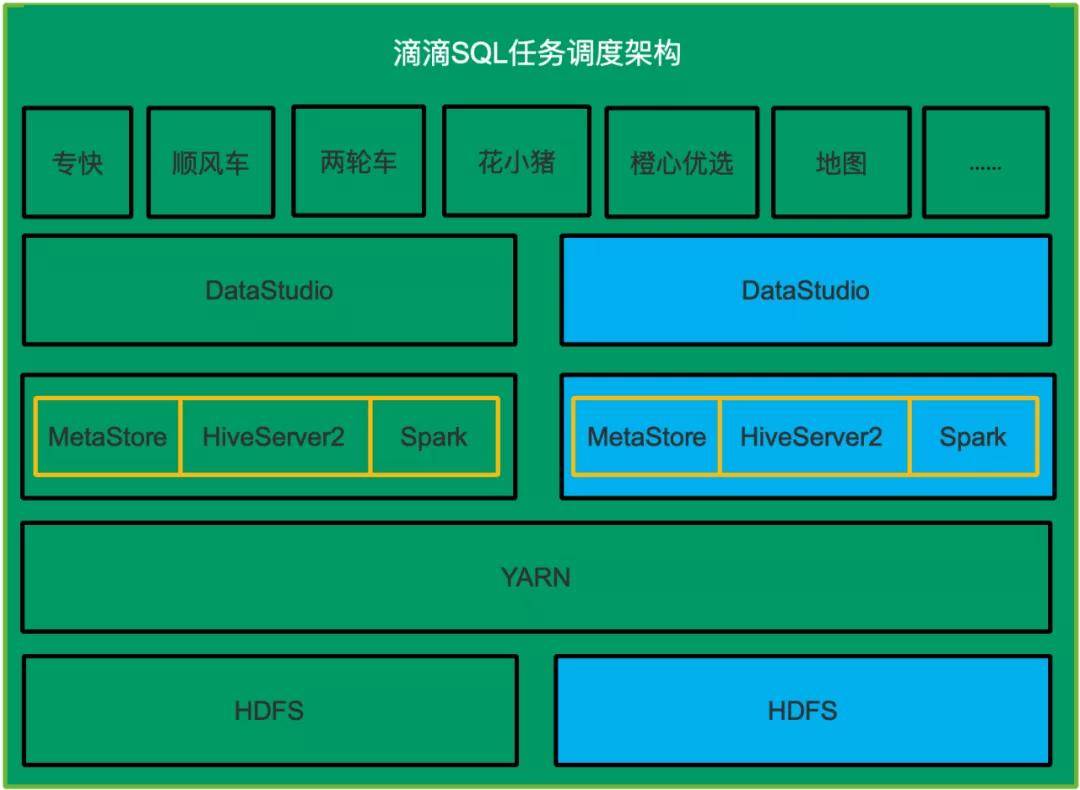
2. 方案二:开发一个SQL双跑工具
SQL双跑工具,可以线下使用两个引擎执行用户的SQL,具体流程如下:
- SQL收集:用户的SQL是在HS2上执行的,所以理论上通过HS2可以收集到所有的SQL;
- SQL改写:执行用户原始SQL会覆盖线上数据,所以在执行前需要改写SQL,把SQL的输出的库表名替换为用来迁移测试的的库表名;
- SQL双跑:分别使用Hive和Spark执行改写后的SQL;
3. 方案对比
1)方案一
① 优势
- 隔离性好,单独的SQL执行系统不会影响生产任务,也不会影响业务数据;
② 劣势
- 需要的资源多:运行多个子系统需要较多物理资源;
- 部署复杂:部署多个子系统,需要多个不同的团队相互配合;
- 容易出错:子系统间需要周期性同步,任何一个子系统同步出问题,都可能导致执行SQL失败;
2)方案二
① 优势
- 非常轻量,不需要部署很多系统,而且对物理资源需要不高;
② 劣势
- 与生产公共一套环境,回放时有影响用户数据对风险;
- 需要开发SQL收集,SQL改写和SQL双跑系统;
经过权衡, 我们决定采用方案二, 因为:
- 通过HiveServer收集所有SQL,SQL改写和SQL双跑逻辑清晰,开发成本可控;
- 创建超读帐号,对所有库表有读权限,但只对用户迁移的测试库有写权限,可以避免影响用户数据的风险;
三、迁移方案详细设计
1. Hive SQL提取
Hive SQL提取包括以下步骤:
- 改造HiveHistoryImpl,每个session内执行的所有SQL和command保存到HiveServer2的一个本地文件中,这些文件按天组织,每天一个目录
官方微信公众号:掌酷门户(wapzknet)
相关资讯
新闻热点
精选美图