SQL任务运行时间省40%,后悔没早从Hive迁到Spark…(5)
2021-06-02 09:45 dbaplus社群
1. 语法差异
有些Hive SQL使用Spark SQL执行在语法分析阶段就会出错,有些语法差异我们在内部版本已经修复,目前正在反馈社区,正在和社区讨论,还有一些目前没有修复。
1)用例设计
- UDTF新版initialize接口支持,对齐Hive SQL [SPARK-33704]
- Window Function 不支持没有order by子句的场景
- Join 子查询支持rand 随机分布条件,增强语法兼容
- Orc/Orcfile 存储类型创建语句屏蔽ROW FORMAT DELIMITED限制 [SPARK-33755]
- `DB.TB` 识别支持,对齐Hive SQL [SPARK-33686]
- 支持CREATE TEMPORARY TABLE
- 各类Hive UDF的支持调用,主要包括get_json_object,datediff,unix_timestamp,to_date,collect_set,date_sub [SPARK-33721]
- DROP不存在的表和分区,Spark SQL报错,Hive SQL 正常 [SPARK-33637]
- 删除分区时支持设置过滤条件 [SPARK-33691]
2)未修复
- Map类型字段不支持GROUP BY操作
- Operation not allowed:ALTER TABLE CONCATENATE
2. UDF差异
在排查数据不一致的SQL过程中,我们发现有些是因为输入数据的顺序不同造成的, 这些差异逻辑上是正确的,而有些是UDF对异常值的处理方式不一致造成的,还有需要注意的是UDF执行环境不同造成的结果差异。
1)顺序差异
这些因为输入数据的顺序不同造成的结果差异逻辑上是一致的,对业务无影响,因此在迁移过程中可以忽略这些差异,这类差异的SQL任务属于经验可迁移。
① collect_set
假设数据表如下:
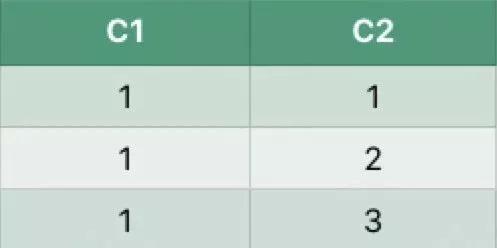
执行如下SQL:

执行结果:
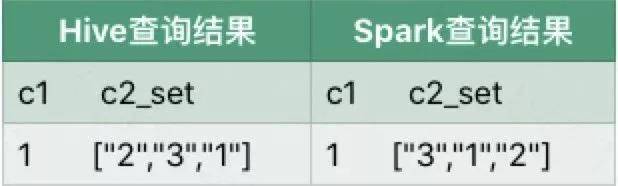
差异说明:
collect_set执行结果的顺序取决于记录被扫描的顺序,Spark SQL执行过程中是多个任务并发执行的,因此记录被读取的顺序是无法保证的。
② collect_list
假设数据表如下:
执行如下SQL:

执行结果:
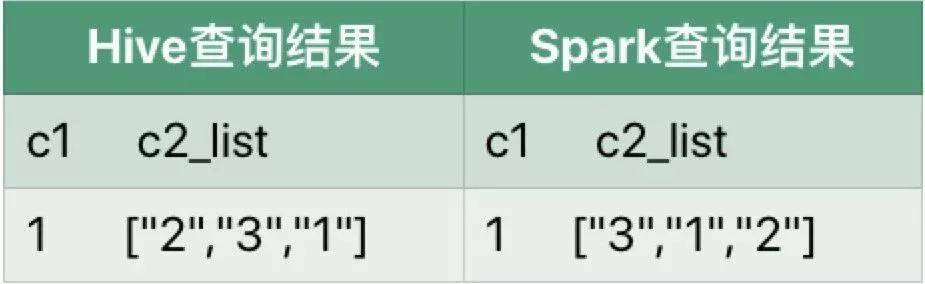
差异说明:
官方微信公众号:掌酷门户(wapzknet)
相关资讯
新闻热点
精选美图