SQL任务运行时间省40%,后悔没早从Hive迁到Spark…(7)
2021-06-02 09:45 dbaplus社群
① datediff
对于异常日期,比如0000-00-00执行datediff两者会存在差异。

② unix_timestamp
对于24点Spark认为是非法的返回NULL,而Hive任务是正常的,下表时执行unix_timestamp(concat('2020-06-01', ' 24:00:00'))时的差异。

③ to_date
当月或者日是00时Hive仍然会返回一个日期,但是Spark会返回NULL。

④ date_sub
当月或者日是00时Hive仍然会返回一个日期,但是Spark会返回NULL。

⑤ date_add
当月或者日是00时Hive仍然会返回一个日期,但是Spark会返回NULL。
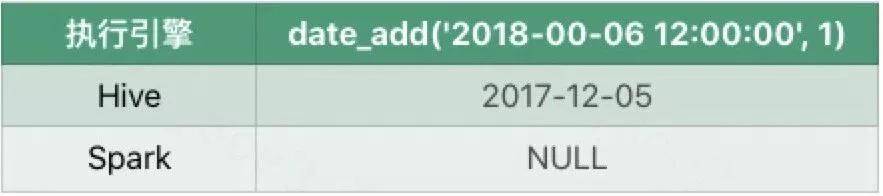
⑥ 非顺序差异解决方案
这些差异是是因为对异常UDF参数的处理逻辑不同造成的,虽然Spark SQL返回NULL更合理,但是现有的Hive SQL任务用户适应了这种处理逻辑,所以为了不影响现有SQL任务,我们对这类UDF做了兼容处理,用户可以通过配置来决定使用Hive内置函数还是Spark的内置UDF。
3)UDF执行环境差异
① 差异说明
基于MapReduce的Hive SQL一个Task会启动一个进程,进程中的主线程负责数据处理, 因此在Hive SQL中UDF只会在单程中执行。
而Spark 一个Executor可能会启动多个Task,如下图所示。因此在Spark SQL中自定义UDF时需要考虑线程安全问题。
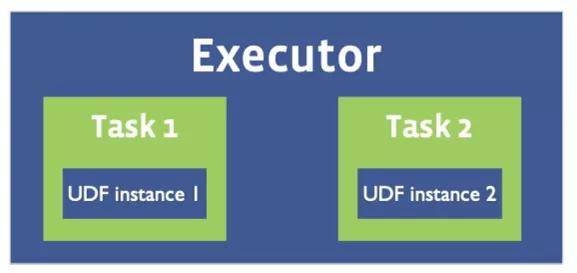
② 差异解决方案
下面是一个非线程安全的示例,UDF内部共享静态变量,在执行UDF时会读写这个静态变量。

解决方案也比较简单,一种是加锁,如下图所示:
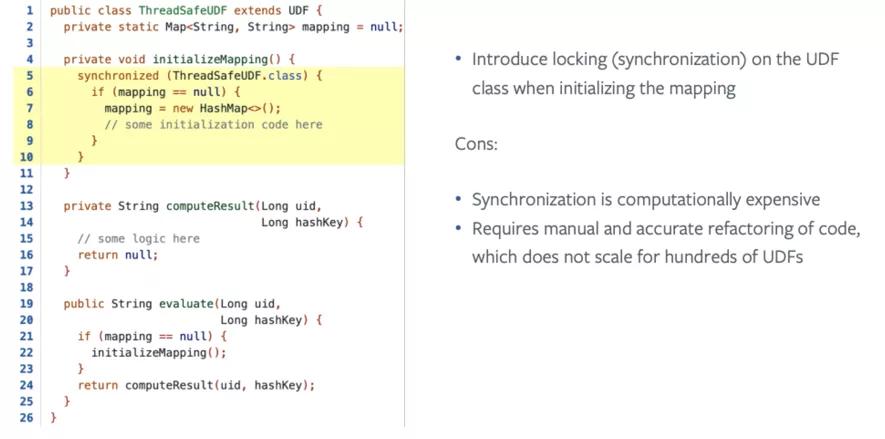
另一种是取消静态成员,如下图所示:

3. 性能&功能差异
官方微信公众号:掌酷门户(wapzknet)
相关资讯
新闻热点
精选美图