SQL任务运行时间省40%,后悔没早从Hive迁到Spark…(6)
2021-06-02 09:45 dbaplus社群
collect_list执行结果的顺序取决于记录被扫描的顺序,Spark SQL执行过程中是多个任务并发执行的,因此记录被读取的顺序是无法保证的。
③ row_number
假设数据表如下:
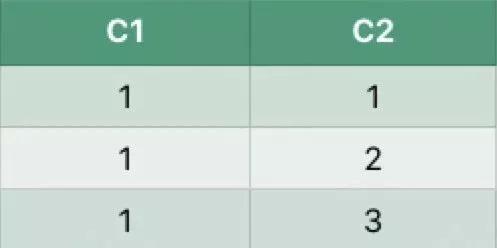
执行如下SQL:

执行结果:
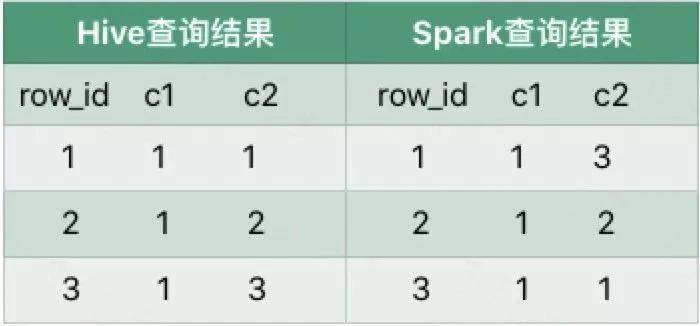
差异说明:
执行row_number时,在一个分区内部,可以保证order by字段是有序的,对于非分区非order by字段的顺序是没有保证的。
④ map类型字段读写
数据表建表语句:

假设数据表如下:
执行如下SQL:
执行结果:

差异说明:
Map类型是无序的,同一份数据,在query时显示的各个key的顺序会有变化。
⑤ sum(double/float)
假设数据表如下:
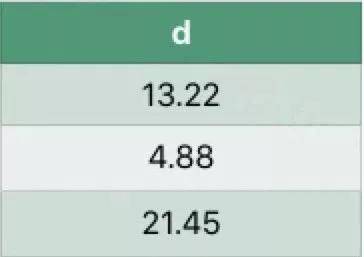
执行如下SQL:

执行结果:
差异说明:
这是由float/double类型的表示方式决定的,浮点数不能表示所有的实数,在执行运算过程中会有精度丢失,对于几个浮点数,执行加法时的顺序不同,结果有时就会不同。
⑥ 顺序差异解决方案
由以上UDF造成的差异可以忽略,相关任务如果在资源方面也有节省,那么最终的状态是经验可迁移状态,符合迁移条件。
2)非顺序差异
下面几个日期/时间相关函数,当有异常输入是Spark SQL会返回NULL,而Hive SQL会返回一个非NULL值。
官方微信公众号:掌酷门户(wapzknet)
相关资讯
新闻热点
精选美图