SQL任务运行时间省40%,后悔没早从Hive迁到Spark…(4)
2021-06-02 09:45 dbaplus社群
- 如果所有对应列的值相同则认为结果一致;
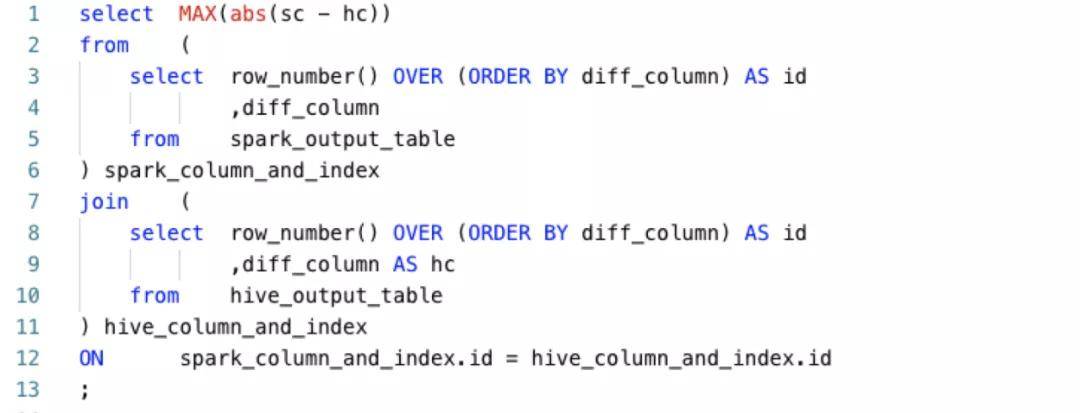
- 如果存在不一致的列,如果该列是数值类型,则对该列计算最大精度差异, SQL如下:
- 统计两种引擎启动的Application消耗的vcore和memory资源;
- 输出对比结果, 包括运行时间, 消耗的vcore和memory,是否一致,如果不一致输出不一致的列名以及最大差异;
- 汇总数据结果,并对回放的SQL分为以下几类:
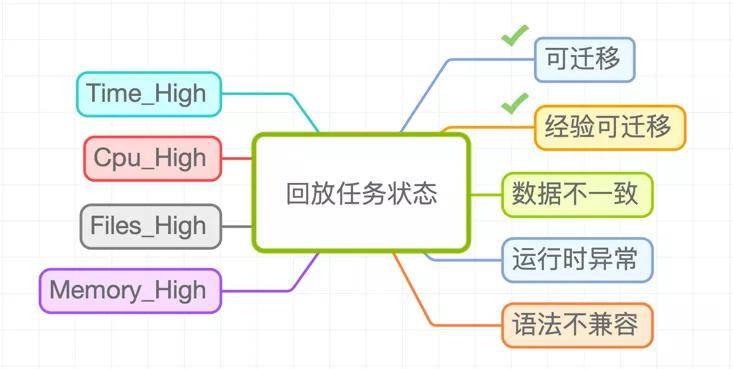
- 可迁移:数据完全一致, 并且使用Spark SQL执行使用更少资源,包括运行时间,vcore和memory以及文件数;
- 经验可迁移:在排查不一致时发现有些是逻辑正确的 (比如collect_set结果顺序不一致),如果有些任务符合这些经验,则认为是经验可迁移;
- 数据不一致:两种引擎产出的结果存在不一致的列,而且没有命中经验;
- Time_High:两种引擎产出的结果完全一致,但是Spark执行SQL的运行时间大于Hive执行SQL的时间;
- Cpu_High:两种引擎产出的结果完全一致,但是Spark执行SQL消耗的cpu资源大于Hive执行SQL消耗的cpu资源;
- Memory_High:两种引擎产出的结果完全一致,但是Spark执行SQL消耗的memory资源大于Hive执行SQL消耗的memory资源;
- Files_High:两种引擎产出的结果完全一致,但是Spark执行SQL产生的文件数大于Hive执行SQL产生的文件数;
- 语法不兼容:在SQL改写阶段解析SQL时报语法错误;
- 运行时异常:在双跑阶段,Hive SQL或者Spark SQL在运行过程中失败;
4. 迁移
迁移比较简单, 步骤如下:
- 整理迁移任务列表以及对应的配置参数;
- 调用DataStudio接口把任务类型修改为SparkSQL类型;
- 重跑任务;
5. 问题排查&修复
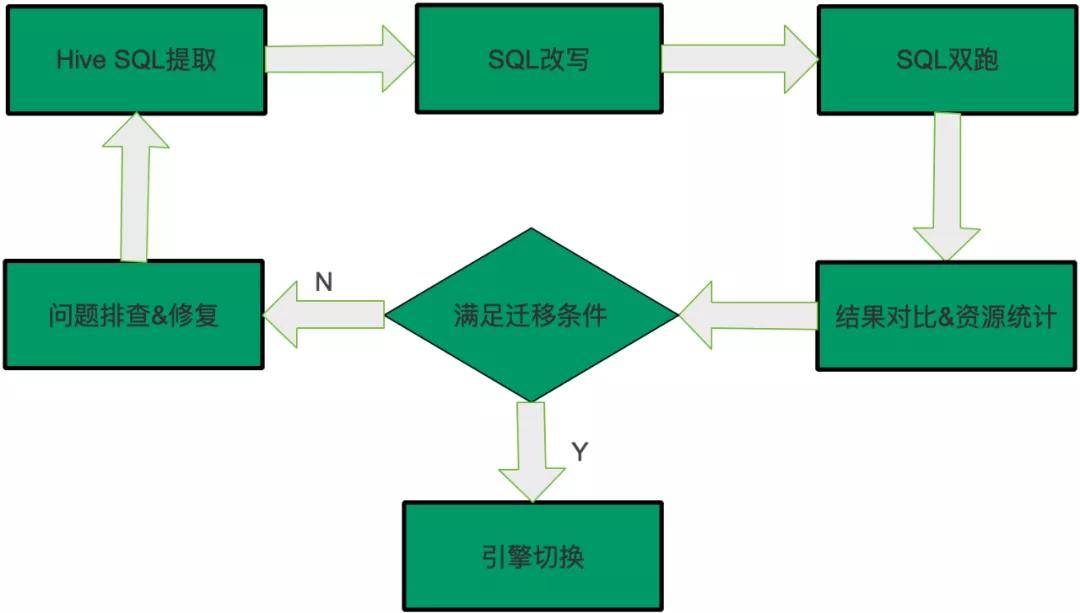
如果SQL是“可迁移”或者“经验可迁移”,可以执行迁移,其它的任务需要排查,这部分是最耗时耗力的,迁移过程中大部分时间都是在调查和修复这些问题。
修复之后再执行从头开始,提取最新任务的SQL,然后SQL改写和双跑,结果对比,满足迁移条件则说明修复了问题,可以迁移,否则继续排查,因此迁移过程是一个循环往复的过程,直到SQL满足迁移条件,整体过程如下图所示:
四、引擎差异
在迁移的过程中我们发现了很多两种引擎不同的地方,主要包括语法差异,UDF差异,功能差异和性能差异。
官方微信公众号:掌酷门户(wapzknet)
相关资讯
新闻热点
精选美图