SQL任务运行时间省40%,后悔没早从Hive迁到Spark…(3)
2021-06-02 09:45 dbaplus社群
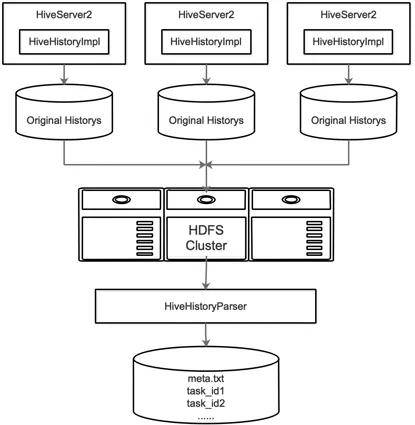
Hive History Parser的主要功能是:
- 每天从HDFS下载所有HiveServer2的History文件;
- SQL去重:DataStudio上的一个SQL任务可能一天执行多次(比如小时任务),任务执行一次会生成一个新的执行Id,只保留一天中最大的执行Id的SQL;
- 合并SQL:一个shell任务可能建立多个session执行SQL,为了后面迁移shell任务,需要把多个session的SQL合并到一起;
- 输出Parse结果:包括多个SQL文件和meta文件:
- 每个任务执行的SQL保存到一个文件中,文件名是任务名称加执行Id,我们称作原始SQL文件;
- meta文件包含SQL文件路径,任务名称,项目名称,用户名;
2. SQL改写&双跑
SQL改写会对上一步生成的每个原始SQL文件执行以下步骤:
- 使用Spark的SessionState对SQL文件逐行分析,识别是否包含以下两类子句:
- insert overwrite into
- create table as select
- 如果包含上面的两类子句,则提取写入的目标库表名称;
- 在测试库中创建与目标库表schema完全一致的两个测试表;
- 分别使用上一步创建的测试库表替换原始SQL文件中的库表名生成用于回放的SQL文件,一个原始SQL文件改写后会生成两个SQL文件,用于后面两个引擎分别执行;
SQL双跑步骤如下:
- 并发的使用Spark和Hive执行上一步生成的两个SQL文件;
- 记录使用两种引擎执行SQL时启动的Application和运行时间;
- 输出回放结果到文件中,执行每个SQL文件对会生成一条结果记录, 包括Hive 和Spark 执行SQL的时间,启动的Application列表,和输出的目标库表名称等, 如下图所示:

3. 结果对比
结果对比时会遍历每个回放记录,统计以下指标:
具体流程如下:
- 查询Spark SQL和Hive SQL输出的库表的记录数;
- 查询两种引擎输出的HDFS文件个数和大小;
- 对比两种引擎的输出数据;
分别对Spark和Hive的产出表执行以下SQL,获取表的概要信息
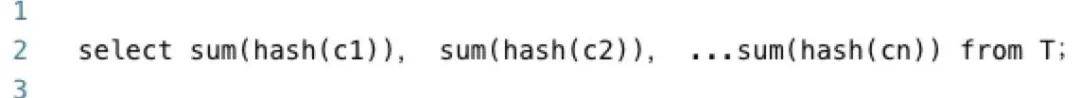
比较两张表的概要信息:
官方微信公众号:掌酷门户(wapzknet)
相关资讯
新闻热点
精选美图